Can you trust your agile planning process to deliver the best result over time?
In an ideal world with a well-balanced and high-performing team, theory says it should all be dandy. But what happens when the real world sticks it's nose in and you need to deal with varying degrees of disfunction?
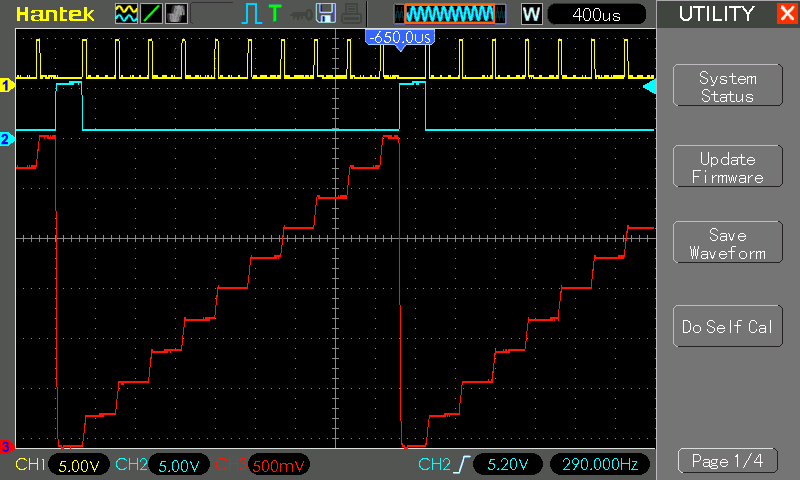
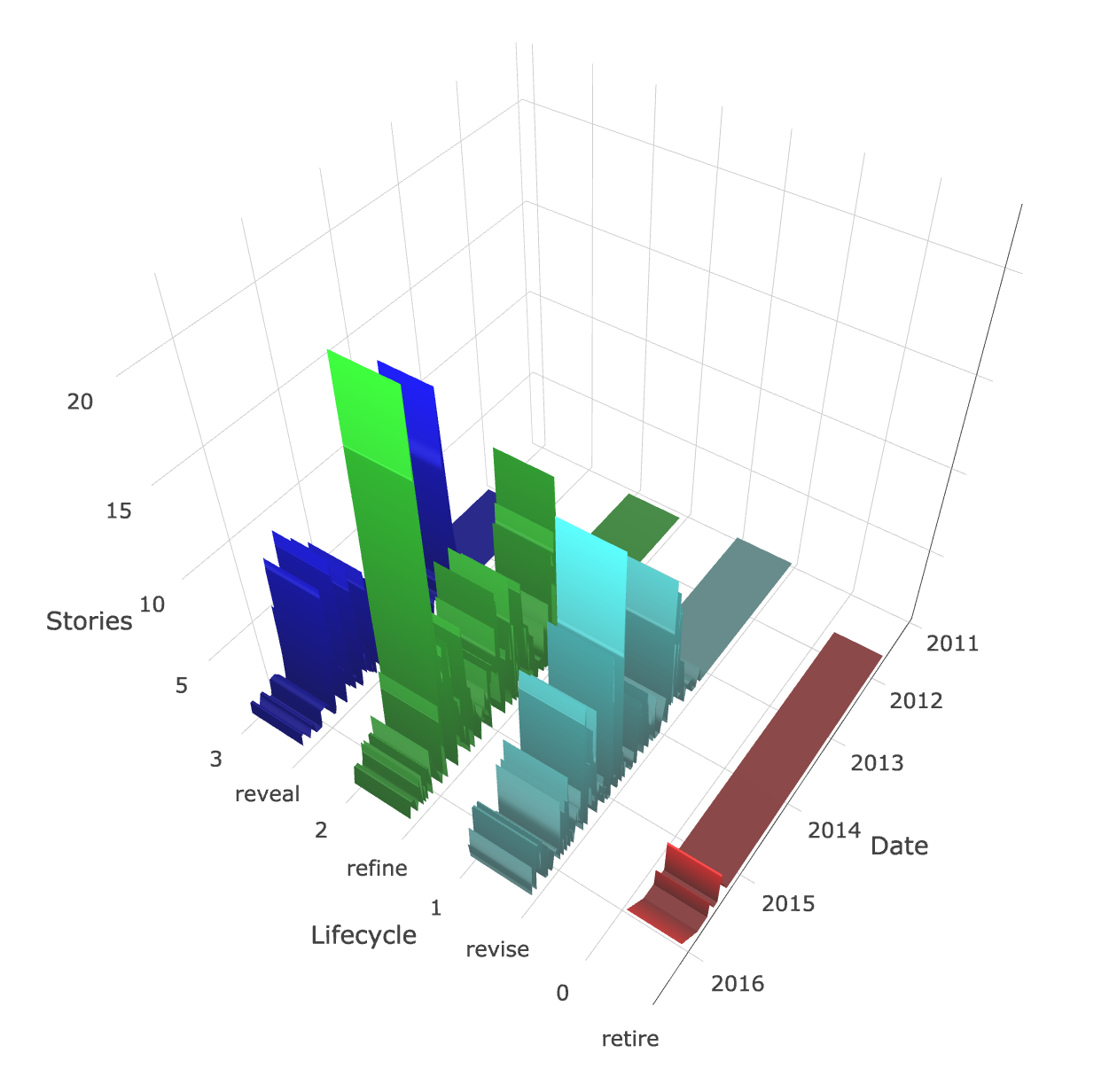
Feature Lifecycle Analysis is a technique I've been experimenting with for a few years. The idea is to visualise how well we are doing as a team at balancing our efforts between new feature development, refinement, maintenance and ultimately feature deprecation.
If you'd like to find out more, and run an analysis on your own projects, try out the
Feature Lifecycle Analysis site. It includes some analysis of two real software development projects, and also a tool for analysing your own PivotalTracker projects.
As always,
all notes, schematics and code are on GitHub.